Linuxで文字コードを変換する方法
2015-02-11
2021-09-15
こんにちは。今回のテーマは『Linuxで文字コードを変換する方法』です。WindowsやMacから送られてきた添付ファイルが文字化けして読めないということはよくあります。大抵の場合は文字コードが異なることで起こります。また、現在のLinuxではUTF-8が主流ですが、EUC-JPを使っているシステムからファイルをコピーしてくると文字化けすることもあります。今回はそんな時も慌てず対応するためのツールを紹介します。 【関連記事】 Linuxで読み込んだUSBメモリが文字化けした時の対処方法 [adsense02]
Windowsから送られてきた添付ファイルが文字化け
では早速Windowsから送られてきた添付ファイル”三四郎.txt”を開いてみましょう。夏目漱石の『三四郎』の冒頭ですが完全に文字化けしてますね。 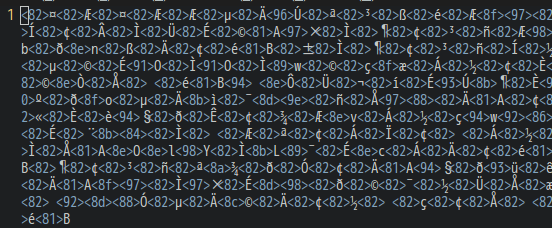 さっぱり読めませんね。これを読めるようにしていきましょう。
さっぱり読めませんね。これを読めるようにしていきましょう。
文字コードを調べる
fileコマンドを使う
まずこのファイルはどの文字コードで書かれているのでしょうか?以下のコマンドで調べられます。
$ file -b <ファイル名>
文字コードとfindコマンドでの表示か以下の通りです
| 文字コード | findコマンドでの表示 |
|---|---|
| EUC | ISO-8859 text |
| Shift-JIS | Non-ISO extended-ASCII text |
| JIS | ASCII text |
| UTF-8 | UTF-8 text |
送られてきたファイルは以下のような結果でした
Non-ISO extended-ASCII text, with CRLF line terminators
つまりShift-JISということですね。もちろんWindwosから送付されたということなので当然なのですが。
nkfを使う方法もある
nkfについては次の項で紹介しますが、文字コードを調べるにも便利なツールです。以下のように使います。
$ nkf —guess <ファイル名>
出力例
Shift_JIS (LF)
iconvを使って文字コードを変換する
まずはiconvを使って変換していきましょう。Linuxユーザーの間ではとても有名なツールですね。基本的な使い方は以下の通りです。
$ iconv -f <エンコーディング> -t <エンコーディング> <ファイル名>
よく使われるエンコーディングには以下があります。
SHIFT_JIS CP932 UTF-8 EUC-JP
全て見たい場合には-lオプションで見ることが出来ます。また、オプションとしては以下が用意されています。
入力/出力形式の指定: -f, —from-code=NAME 元のテキストのエンコーディング -t, —to-code=NAME 出力用のエンコーディング
情報: -l, —list 全ての既知の符号化された文字集合を一覧表示します
出力制御: -c 出力から無効な文字を取り除く -o, —output=FILE 出力ファイル -s, —silent 警告を抑制する —verbose 経過情報を表示する
-?, —help このヘルプ一覧を表示する —usage 短い使用方法を表示する -V, —version プログラムのバージョンを表示する
変換結果を別ファイルに出力する
iconvは変換結果を出力するコマンドですので、ファイルに出力する必要があります。ファイルAの文字コードを変換してファイルBを作る場合は以下のコマンドを実行します。
$ iconv -f <エンコーディング> -t <エンコーディング> <ファイルA> -o ファイルB または
具体的な使い方
さて、Windowsから送信された”三四郎.txt”をUTF-8のconvfile.txtに変換します。
$ iconv -f SHIFT_JIS -t UTF-8 三四郎.txt -o convfile.txt
nkfを使って文字コードを変換する
もうひとつの有名なツールがnkfです。nkfではメジャーなディストロでは大抵パッケージとして用意していると思います。nkfの基本的なコマンドは以下の通りです。
$ nkf [オプション] <ファイル名>
このオプションで変換後の文字コードを決めます。細かいオプションはHelpを見ていただくとして文字コード変換に取り敢えず必要なオプションは以下の通りです。
-j : ISO-2022-JP に変換 -s : Shift_JIS に変換 -e : EUC-JP に変換 -w : UTF-8 に変換
例えばfile.txtの内容をUTF-8で出力するには
$ nkf -w file.txt
となります。
変換結果を別ファイルに出力する
iconvと同じくnkfも結果を標準出力に出力するのでファイルに書き出すには以下のようなコマンドとなります。
$ nkf [オプション] <ファイルA> > <ファイルB>
具体的な使い方
では先ほどと同じくWindowsから送信された”三四郎.txt”をnkfでUTF-8に変換してみます。
$ nkf -w 三四郎.txt > convfile.txt
では変換されたconvfile.txtを見てみます。
うとうととして目がさめると女はいつのまにか、隣のじいさんと話を始めている。このじいさんはたしかに前の前の駅から乗ったいなか者である。発車まぎわに頓狂な声を出して駆け込んで来て、いきなり肌をぬいだと思ったら背中にお灸のあとがいっぱいあったので、三四郎の記憶に残っている。じいさんが汗をふいて、肌を入れて、女の隣に腰をかけたまでよく注意して見ていたくらいである。
(夏目漱石著 三四郎より引用)
番外編 Vimの文字コード変換を使う
vimでも文字コードを扱うことが出来ます。簡単に紹介しておきます。 文字コードを指定してファイルを開き直す
:e ++enc=[エンコーディング]
文字コードを指定する
:set fenc=[エンコーディング]
以上の動作を組み合わせることでファイルの文字コードを変換することが出来ます。 エンコーディングには主に以下のものがあります。
cp932 shift_jis euc-jp utf8
最後に
最近Windowsから送られてきたメールの添付ファイルが文字化けしていたり、自分がMacで以前に作成したテキストファイルが文字化けしていたため備忘録として記事を書きました。文字コードについては歴史的な背景もあり非常に複雑です。Linux関連はunicodeで一本化していくでしょうが、まだまだこの問題が収束するには時間がかかりそうです。 [adsense]